머신러닝(Machine Learning)이란?
- 규칙을 일일이 프로그래밍 하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야
- 보통의 프로그램과 달리 누구도 알려주지 않는 기준을 찾아서 일을 함
대표적인 머신러닝 라이브러리
- 사이킷런(scikit-learn) : 파이썬 API를 사용
Google Colab
- 머신러닝을 학습하기 위한 서비스
구글 코랩으로 머신러닝 실습해보기
'생선 분류 문제' - 도미와 빙어를 분류하기(이진 분류 : 2개의 클래스 중 하나를 고르는 문제)
1. 도미와 빙어 데이터 준비
위는 도미와 빙어의 길이 및 무게 데이터를 나타낸 것이다. Bream은 도미를 의미하고, Smelt는 빙어를 의미한다.
2. 산점도 이용
- 데이터를 그래프로 표현해서 보다 더 편하게 볼 수 있게 산점도를 이용한다.
- 여기서 산점도는 x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법이다.
- 산점도를 표현하기 위해 matplotlib 패키지를 이용한다.
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()scatter() : 산점도를 그리는 함수

3. k-Nearest Neighbors를 이용해 도미와 빙어 구분
- 머신러닝 패키지인 사이킷런을 이용한다.
- 사이킷런을 사용하기 위해 2차원 리스트를 만들어야 한다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l,w] for l, w in zip(length,weight)]zip() 함수와 리스트 내포 구문을 사용한다. zip() 함수는 나열된 리스트 각각에서 하나씩 원소를 꺼내 반환한다. for문은 zip() 함수에서 길이와 무게 리스트에서 하나씩 꺼내 l과 w에 할당하고 그 결과, [l, w]가 하나의 원소로 구성된 리스트가 만들어진다.
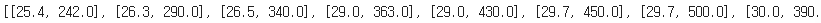
도미와 빙어를 각각 숫자 1과 0으로 표현한다.
fish_target = [1]*35 + [0]*14
k-Nearest Neighbors 알고리즘을 구현한 클래스 KNeighborsClassifier를 이용한다. kn은 클래스의 객체다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data,fish_target)
kn.score(fish_data, fish_target)fit() : 모델에 데이터를 전달해 규칙을 학습하는 과정을 뜻하는 훈련 메소드이다. 즉, 주어진 데이터로 알고리즘을 훈련한다.
score() : 모델을 평가하는 메서드로, 0~1 사이의 값을 반환한다. 1은 모든 데이터를 정확히 맞혔다는 것을 나타낸다.
위의 결과는 1.0이다. 모든 fish_data의 답을 정확히 맞혔다는 뜻이다. 이 값을 정확도라고 한다. 정확도는 100%이며, 도미와 빙어를 완벽히 분류했다.
정확도 = (정확히 맞친 개수) / (전체 데이터 개수)
위에서 사용한 알고리즘은 k-최근접 이웃이다. 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 것이다.

kn.predict([[30,600]])위 코드는 삼각형의 위치를 나타낸 것이다. 결과는 array([1])이 나온다.
predict() : 새로운 데이터의 정답을 예측하는 메서드이다. 2차원 리스트를 전달해야 한다.
'혼공 > 머신러닝' 카테고리의 다른 글
| 3장 회귀 알고리즘과 모델 규제 (0) | 2022.08.13 |
|---|---|
| 2장 데이터 다루기 (0) | 2022.07.22 |